sharing, publishing, archiving
Karen Cranston, Hilmar Lapp
URL to lesson:
https://github.com/Reproducible-Science-Curriculum/rr-publication

To the extent possible under law,
the person who associated CC0
with this work has waived all copyright and related or neighboring
rights to this work.
This work is published from:
United States.
Non synomymous
why, what, when, where, how, with whom to share & publish?
why publish, share, archive?
why?
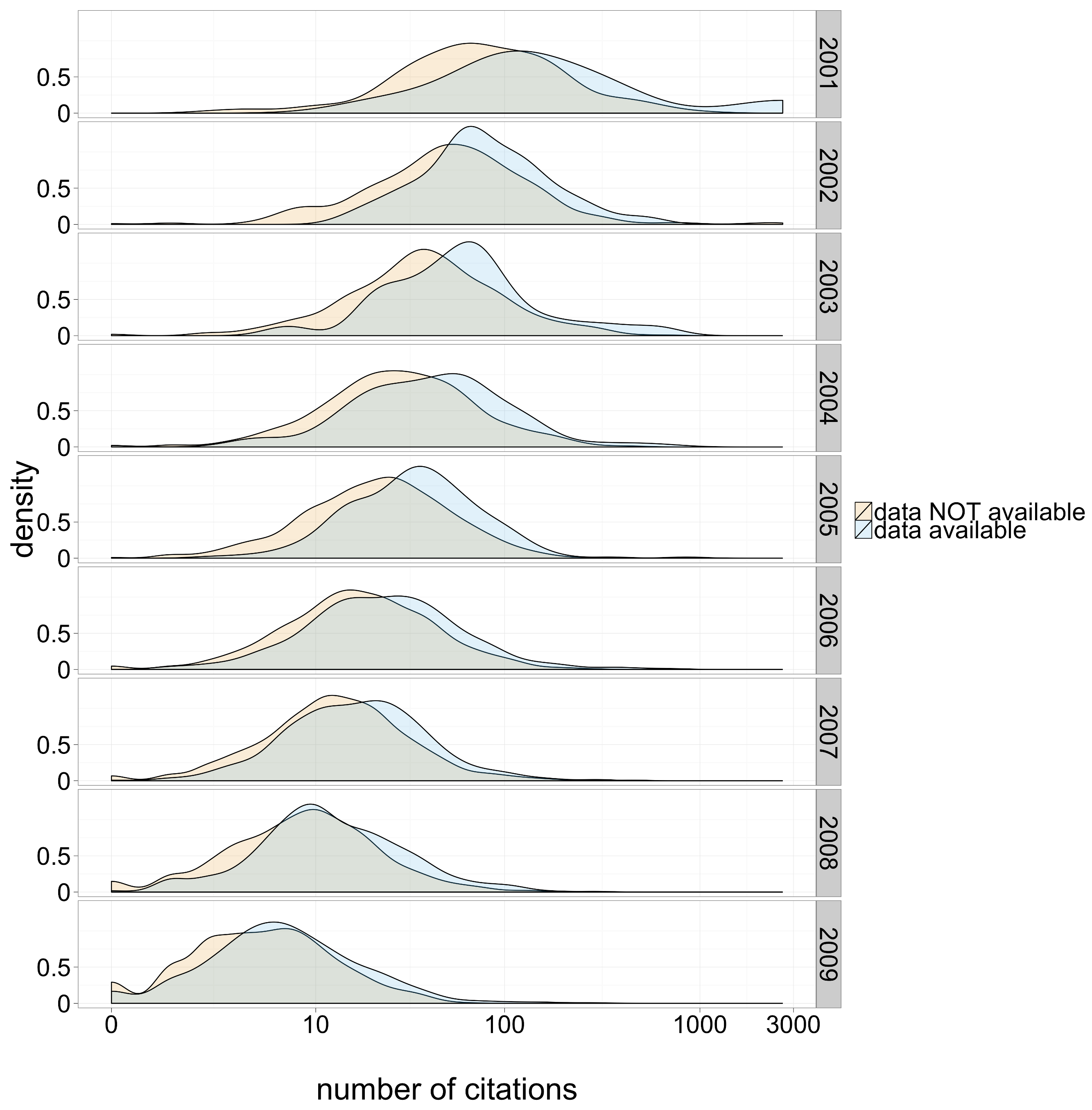
increased visibility / citation
why?
better research
why?
Activity (in pairs)
it depends
where?
![]()

how to choose?
what goes where when?
how to share, publish: file formats
how to share, publish: checklist
Activity (in pairs)
does copyright apply?
Choose A License
software licensing guide
open is not open to interpretation
Waiving copyright

CC0 enables scientists, educators, artists and other creators and owners of copyright- or database-protected content to waive those interests in their works and thereby place them as completely as possible in the public domain, so that others may freely build upon, enhance and reuse the works for any purposes without restriction under copyright or database law.